```{r}
#| echo = FALSE
suppressPackageStartupMessages(library(tidyverse))
library(rvest)
library(knitr)
opts_chunk$set(cache.path = "class_3_files/class_3_cache/html/")
```
## Recordemos como es una página htm {.smaller}
:::: {.columns}
::: {.column width="50%"}
- *Elementos*: tags como `title`, `h1`, o `p` que parten y terminan
- *Atributos*:
- nombres: `id`
- clases para CCS: `class`
- *Contenido*: Lo que queda dentro de los elementos.
:::
::: {.column width="50%"}
```html
Título de página
Un encabezado
Algún texto & texto en negrita.
```
:::
::::
## Página web con la que trabajaremos {.smaller}
:::: {.columns}
::: {.column width="50%"}
- `h#`: encabezados. Niveles de `h1` a `h6`
- `p`: párrafos
- `img`: imagen. Requiere el atributo `src` (no tiene cierre)
- `table`: tablas
- `a`: link (*anchor*). Requiere el atributo `href`
- ` `: salto de línea (no tiene cierre)
:::
::: {.column width="50%"}
```html
Datos de perros
```
[HTML Elements](https://www.w3schools.com/html/html_elements.asp)
:::
::::
## El desafio: encontrar lo que nos interesa.
Podemos utilizar varias formas de llegar a ellos:
* Elementos de html por su [`tag`](https://www.w3schools.com/tags/ref_byfunc.asp)
* Mediante selectores de [`css`](https://www.w3schools.com/css/css_selectors.asp)
* `id` que identifica de manera única algún elemento web
* `clases` de estilos
* Combinación de `tags` y `clases`
## Librería: rvest {.smaller}
[Referencia](https://rvest.tidyverse.org/reference/index.html) de funciones en [rvest](https://rvest.tidyverse.org/reference/index.html) a tener en cuenta
- `xlm2::read_html()`: función exportada por `rvest` para leer páginas web.
- `html_element()` o `html_elements()`: extrae elementos
- `html_attr()` o `html_attrs()`: extraemos atributos
- `html_children()`: extrae elementos bajo cierto nodo
- `html_name()`: extrae el nombre de elementos
- `html_table()`: extrae y transforma a una data frame una tabla html
- `html_text()` o `html_text2()`: extrae texto o contenido
## html con tabla {.smaller}
```{r}
#| echo: false
if(interactive()){
url <- 'class_3_files/scraping_con_css.html'
} else {
url <- 'class_3_files/scraping_con_css.html'
}
page <- htmltools::includeHTML(url) # Guardar el texto del html de la url.
page |> gsub('\n', '', x = _)
```
## Scraping: lectura en R de html con datos
Luego leemos la página en R usando `rvest`.
::: {.smaller}
```{r}
#| echo: true
# read_html(page)
(html1 <- rvest::read_html(x = url)) # Leer la url directamente.
```
:::
## Scraping: tablas
Podemos capturar las tablas con el tag `
` de la página:
```{r}
html1 |> html_elements('table') |> html_table()
```
¿Como podemos ser más **_selectivos_**?
## Selectores de CSS
[CSS Selector Reference](https://www.w3schools.com/CSSref/css_selectors.asp)
* `#id`: elemento de id = `id`
* `tag`: elementos de tipo ``
* `.class`: elementos de clase `class`
* `tag.class`: elementos de tipo `tag` de clase `class`
Se revisar su funcionamiento [en un ejemplo](https://www.w3schools.com/CSSref/trysel.asp)
y entrenar habilidades en [CSS Diner](https://flukeout.github.io).
## Selectores de CSS: nombres
Analicemos la [página web](./class_3_files/scraping_con_css.html) directamente.
Para encontrar los elementos de interés en la página web, usamos dos herramientas:
- [SelectorGadget](https://rvest.tidyverse.org/articles/selectorgadget.html):
Un programa en javascript que puede quedar como [bookmarklet](https://en.wikipedia.org/wiki/Bookmarklet).
- [Web development tools](https://en.wikipedia.org/wiki/Web_development_tools) del navegador de preferencia.
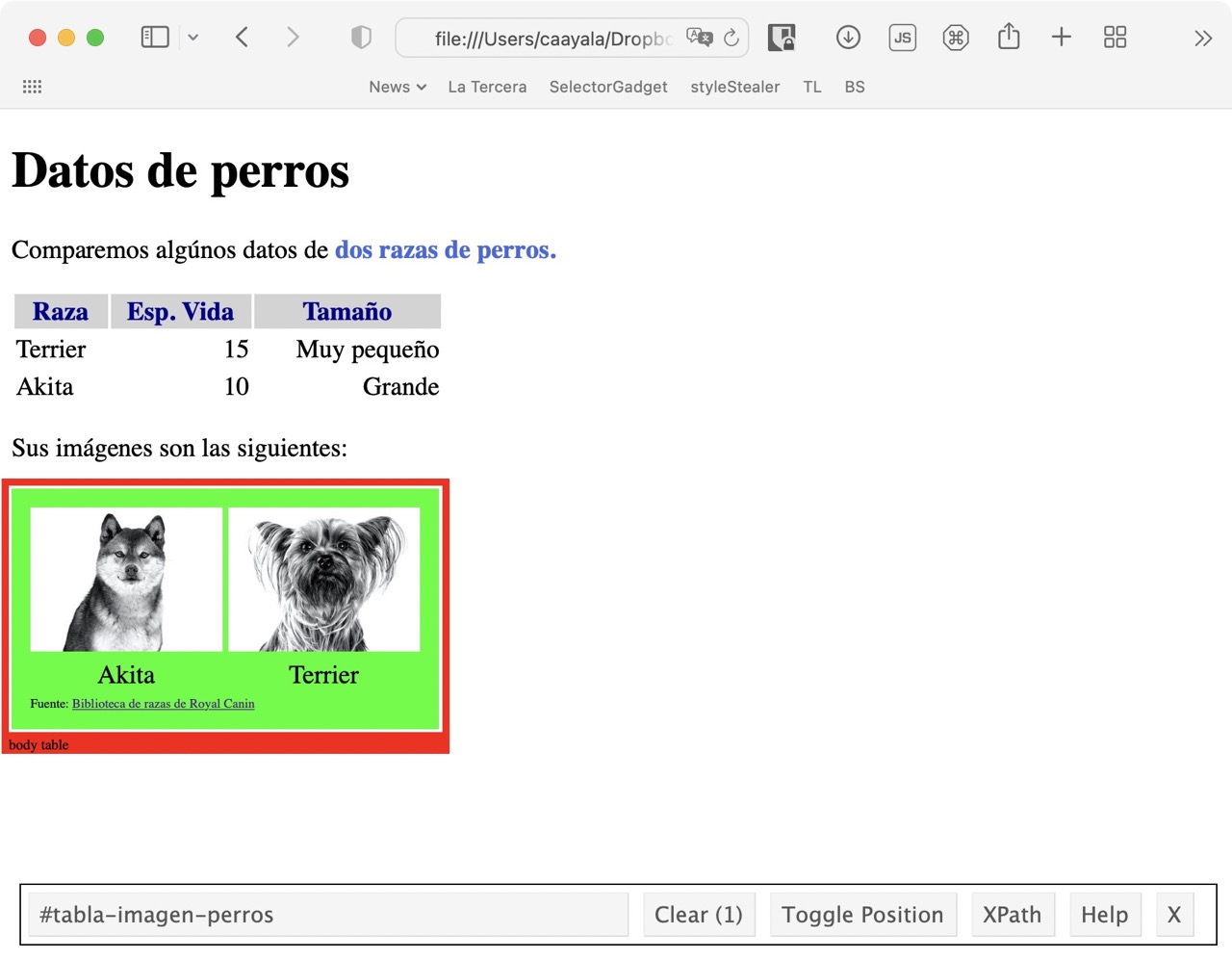
## Identificación de elementos: SelectorGadget
- [SelectorGadget](https://rvest.tidyverse.org/articles/selectorgadget.html)
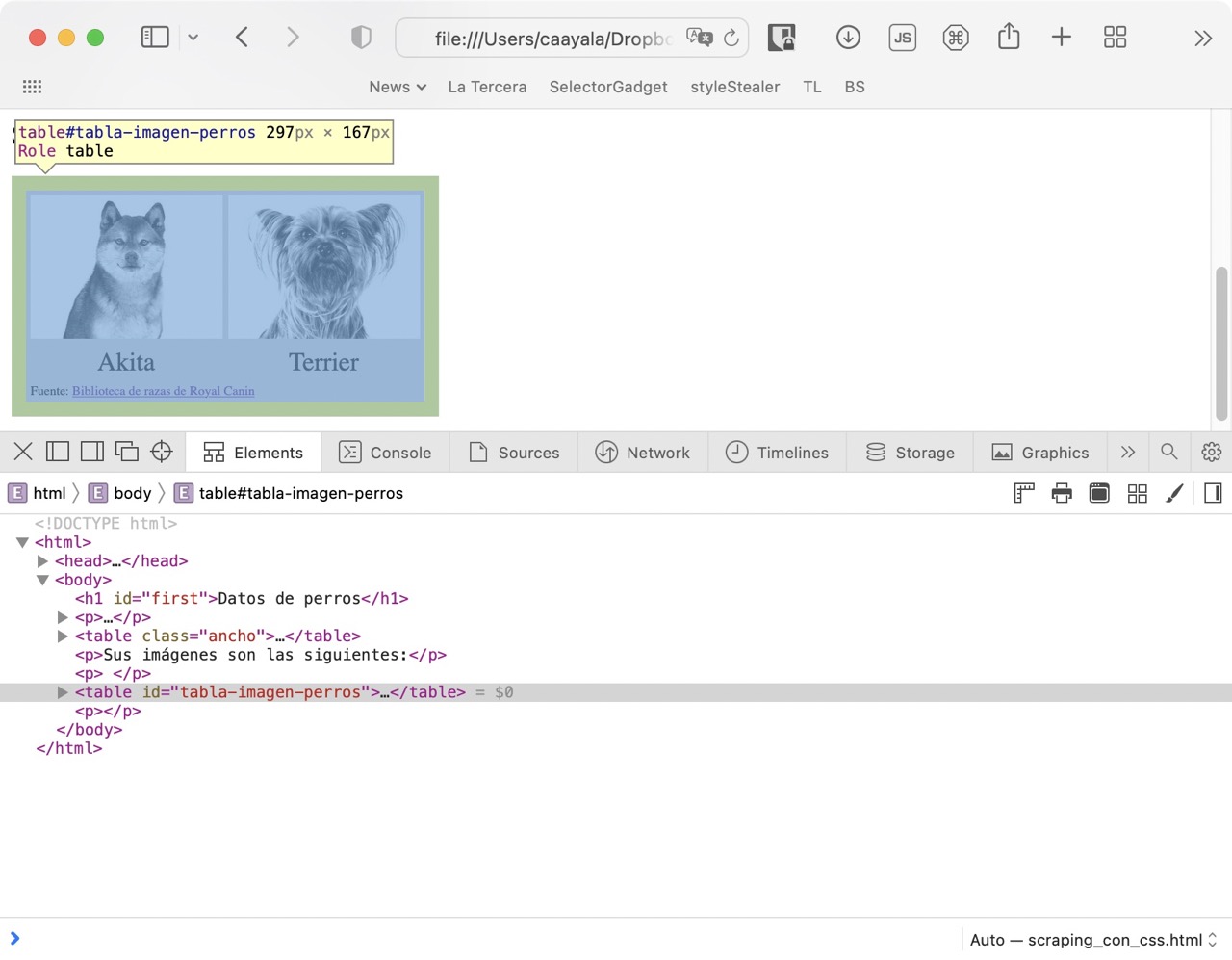
## Identificación de elementos: Web development tools
- [Web development tools](https://en.wikipedia.org/wiki/Web_development_tools) del navegador de preferencia.
## Scraping: tabla según id 1
La segunda tabla tiene como id: `#tabla-imagen-perros`
```{r}
(df_img_perros <- html1 |>
html_element('#tabla-imagen-perros') |>
html_table())
```
¿Cómo capturamos los links a las imágenes?
```{r}
(src_img_perros <- html1 |> html_elements('#tabla-imagen-perros') |>
html_elements('img') |>
html_attr('src'))
```
## Scraping: tabla según id 2
Se debe saber cómo manejar distintas secciones de los datos.
```{r}
# Uso rbind porque tiene menos salvaguardas que `bind_rows`.
(df_img_perros <- base::rbind(df_img_perros,
src_img_perros))
```
Queda pivotear la base.
```{r}
df_img_perros |>
t() |> as.data.frame() |>
setNames(nm = c('raza', 'fuente', 'img_src'))
```
## Scraping: texto 1
- Seleccionar elemento identificado con `id = first`
```{r}
html1 |> html_element('#first') |> html_text()
```
- Selección de todos los `
`
```{r}
html1 |> html_elements('p') |> html_text()
```
- Selección de `` dentro de `

