req_wiki_api <-request('https://es.wikipedia.org') |>req_url_path('w/api.php') |>req_headers('Accept-Encoding'='gzip')req_wiki_search <- req_wiki_api |>req_url_query(!!!list(action ='query',list ='search',srsearch ='web scraping',srlimit =5,format ='json'))resp_wiki_search <-req_perform(req_wiki_search)# Leo el json que está dentro de la respuesta a la petición.df <- resp_wiki_search |>resp_body_json(simplifyVector = T)df |>str()
List of 3
$ batchcomplete: chr ""
$ continue :List of 2
..$ sroffset: int 5
..$ continue: chr "-||"
$ query :List of 2
..$ searchinfo:List of 1
.. ..$ totalhits: int 25
..$ search :'data.frame': 5 obs. of 7 variables:
.. ..$ ns : int [1:5] 0 0 0 0 0
.. ..$ title : chr [1:5] "Web scraping" "Screen scraping" "Scrapy" "HtmlUnit" ...
.. ..$ pageid : int [1:5] 5544299 1194524 9214341 4481985 6269318
.. ..$ size : int [1:5] 12083 1116 2195 3652 2420
.. ..$ wordcount: int [1:5] 1553 153 142 309 162
.. ..$ snippet : chr [1:5] "<span class=\"searchmatch\">Web</span> <span class=\"searchmatch\">scraping</span> o raspado <span class=\"sear"| __truncated__ "casos, es al contrario, como en los sistemas de captcha). La traducción aproximada de screen <span class=\"sear"| __truncated__ "por Scrapinghub Ltd., una empresa que ofrece productos y servicios de <span class=\"searchmatch\">web</span>-<s"| __truncated__ "páginas <span class=\"searchmatch\">web</span>, pero a veces se puede utilizar para <span class=\"searchmatch\""| __truncated__ ...
.. ..$ timestamp: chr [1:5] "2024-06-12T18:29:53Z" "2019-07-13T13:59:58Z" "2021-10-08T07:29:04Z" "2024-03-08T03:46:36Z" ...
Wikipedia: API buscar API: Search 2
Transformación de los resultados a una tibble. La información que interesa está en query ↘️ search.
Obtención del contenido de página. GET para la acción Parse.
req_wiki_parse <- req_wiki_api |>req_url_query(!!!list(action ='parse',page ='Web scraping', # contenido de título de páginaprop ='text', # html de retornoformat ='json'))resp_wiki_parse <-req_perform(req_wiki_parse)df_wiki_parse <- resp_wiki_parse |>resp_body_json(simplifyVector = T)df_wiki_parse |>str(3)
List of 1
$ parse:List of 3
..$ title : chr "Web scraping"
..$ pageid: int 5544299
..$ text :List of 1
.. ..$ *: chr "<div class=\"mw-content-ltr mw-parser-output\" lang=\"es\" dir=\"ltr\"><p><i><b>Web scraping</b></i> o <b>raspa"| __truncated__
Web scraping o raspado web es una técnica utilizada mediante programas de software para extraer información de sitios web.[1] Usualmente, estos programas simulan la navegación de un humano en la World Wide Web ya sea utilizando el protocolo HTTP manualmente, o incrustando un navegador en una aplicación.
El web scraping está muy relacionado con la indexación de la web, la cual indexa la información de la web utilizando un robot y es una técnica universal adoptada por la mayoría de los motores de búsqueda. Sin embargo, el web scraping se enfoca más en la transformación de datos sin estructura en la web (como el formato HTML) en datos estructurados que pueden ser almacenados y analizados en una base de datos central, en una hoja de cálculo o en alguna otra fuente de almacenamiento. Alguno de los usos del web scraping son la comparación de precios en tiendas, la monitorización de datos relacionados con el clima de cierta región, la detección de cambios en sitios webs y la integración d...
# A tibble: 2 × 18
name pageid ns title contentmodel pagelanguage pagelanguagehtmlcode
<chr> <int> <int> <chr> <chr> <chr> <chr>
1 2330 2330 0 Python wikitext es es
2 5544299 5544299 0 Web scra… wikitext es es
# ℹ 11 more variables: pagelanguagedir <chr>, touched <chr>, lastrevid <int>,
# length <int>, protection <lgl>, restrictiontypes <list>, talkid <int>,
# fullurl <chr>, editurl <chr>, canonicalurl <chr>, displaytitle <chr>
Wikipedia: usando WikipediR 3
Captura de página sobre web scraping en español.
cont_wiki <-page_content(language ='es', project ='wikipedia', page_name ='Web_scraping')str(cont_wiki) # Una lista parse con 4 elementos dentro
List of 1
$ parse:List of 4
..$ title : chr "Web scraping"
..$ pageid: int 5544299
..$ revid : int 160710540
..$ text :List of 1
.. ..$ *: chr "<div class=\"mw-content-ltr mw-parser-output\" lang=\"es\" dir=\"ltr\"><p><i><b>Web scraping</b></i> o <b>raspa"| __truncated__
- attr(*, "class")= chr "pcontent"
Wikipedia: usando WikipediR 4
Texto sobre web scraping.
cont_wiki$parse$text$`*`|># Texto del requerimientoread_html() |>html_text() |>str_trunc(width =1e3) |>cat()
Web scraping o raspado web es una técnica utilizada mediante programas de software para extraer información de sitios web.[1] Usualmente, estos programas simulan la navegación de un humano en la World Wide Web ya sea utilizando el protocolo HTTP manualmente, o incrustando un navegador en una aplicación.
El web scraping está muy relacionado con la indexación de la web, la cual indexa la información de la web utilizando un robot y es una técnica universal adoptada por la mayoría de los motores de búsqueda. Sin embargo, el web scraping se enfoca más en la transformación de datos sin estructura en la web (como el formato HTML) en datos estructurados que pueden ser almacenados y analizados en una base de datos central, en una hoja de cálculo o en alguna otra fuente de almacenamiento. Alguno de los usos del web scraping son la comparación de precios en tiendas, la monitorización de datos relacionados con el clima de cierta región, la detección de cambios en sitios webs y la integración d...
Spotify
Uno de los mayores proveedores de servicio de música del mundo. Tiene disponible una API para la integración de su servicio con otras aplicaciones. Podemos usarla para obtener información.
# A tibble: 8 × 4
id name popularity total
<chr> <chr> <int> <int>
1 6XyY86QOPPrYVGvF9ch6wz Linkin Park 84 25596223
2 0L8ExT028jH3ddEcZwqJJ5 Red Hot Chili Peppers 82 20841924
3 2ye2Wgw4gimLv2eAKyk1NB Metallica 81 27371357
4 5eAWCfyUhZtHHtBdNk56l1 System Of A Down 79 10804883
5 3qm84nBOXUEQ2vnTfUTTFC Guns N' Roses 78 30909210
6 58lV9VcRSjABbAbfWS6skp Bon Jovi 78 13365004
7 6Ghvu1VvMGScGpOUJBAHNH Deftones 78 5562651
8 6wWVKhxIU2cEi0K81v7HvP Rammstein 79 9797108
Spotify: spotifyr 1
Envuelve los llamados a la API de Spotify en funciones de R. Puede verse su referencia
# A tibble: 8 × 4
id name popularity followers.total
<chr> <chr> <int> <int>
1 6XyY86QOPPrYVGvF9ch6wz Linkin Park 84 25596223
2 0L8ExT028jH3ddEcZwqJJ5 Red Hot Chili Peppers 82 20841924
3 6Ghvu1VvMGScGpOUJBAHNH Deftones 78 5562651
4 2ye2Wgw4gimLv2eAKyk1NB Metallica 81 27371357
5 1Ffb6ejR6Fe5IamqA5oRUF Bring Me The Horizon 81 5636152
6 5eAWCfyUhZtHHtBdNk56l1 System Of A Down 79 10804883
7 6FBDaR13swtiWwGhX1WQsP blink-182 77 8259069
8 6deZN1bslXzeGvOLaLMOIF Nickelback 77 6813256
Spotify: spotifyr 2
Cambiamos los criterios de búsqueda para encontrar podcasts.
# A tibble: 10 × 4
id name total_episodes description
<chr> <chr> <int> <chr>
1 1KPSWSt5L85YeoD936e4Ui ¿Cómo Están Los Weones? 32 ¿Cómo Está…
2 4OtyxH4rxMjxXwk0cUKoQ8 Primerizas El Podcast 58 Quieres ap…
3 0vh85smSITYmlWbtcABtzC Expertas en Nada 100 Una charla…
4 5T6nge86sgwXW0TnpNoLTY Tu Desarrollo Personal 180 Desarrollo…
5 2xV7Vx7NQgAC8vMt2vZNnE El Podcast de Marian Rojas… 43 Marian Roj…
6 6uiXpyl749yOE2vs8sCrdW Paranormal 165 Canal de i…
7 129qqeXnPDkEHVfQCmxIQa Cariño Podcast 59 Paula y Ro…
8 6U02wirujU8zNsDQcbPJhS Tomás Va A Morir 224 3 Amigos q…
9 2EVTmMTfBLV9U8WOv8YPzL PSICOLOGÍA DEL ÉXITO 29 Un espacio…
10 5ycEEouNP3fB4emhae3tGE Decretum Podcast 200 Bienvenido…
df_top <-get_playlist('37i9dQZEVXbL0GavIqMTeb') # ID de la lista.df_top_track <- df_top$tracks$items |>as_tibble()suppressMessages(# Seleccionar y limpiar solo alguna de las variables disponibles df_top_track_sel <- df_top_track |>mutate(track.id, track.name, track.popularity, track.album.release_date, name =map(track.album.artists, 'name'),.keep ='none') |>unnest_wider(col = name, names_sep ='_'))df_top_track_sel |>head()
# A tibble: 6 × 7
track.id track.name track.popularity track.album.release_…¹ name_1 name_2
<chr> <chr> <int> <chr> <chr> <chr>
1 5Uptvz6j1sjD… SI NO ES … 85 2024-05-23 Cris … <NA>
2 1pymWRCuZfCd… REAL GANG… 87 2024-05-23 Trueno <NA>
3 3yLoXi85lSf0… MUJER FINA 71 2024-05-30 Jere … <NA>
4 6XjDF6nds4DE… Gata Only 94 2024-02-02 Floyy… Cris …
5 21hsqOOUfdSj… No Ponga … 62 2024-06-20 Cris … <NA>
6 6WatFBLVB0x0… Si Antes … 76 2024-06-21 KAROL… <NA>
# ℹ abbreviated name: ¹track.album.release_date
# ℹ 1 more variable: name_3 <chr>
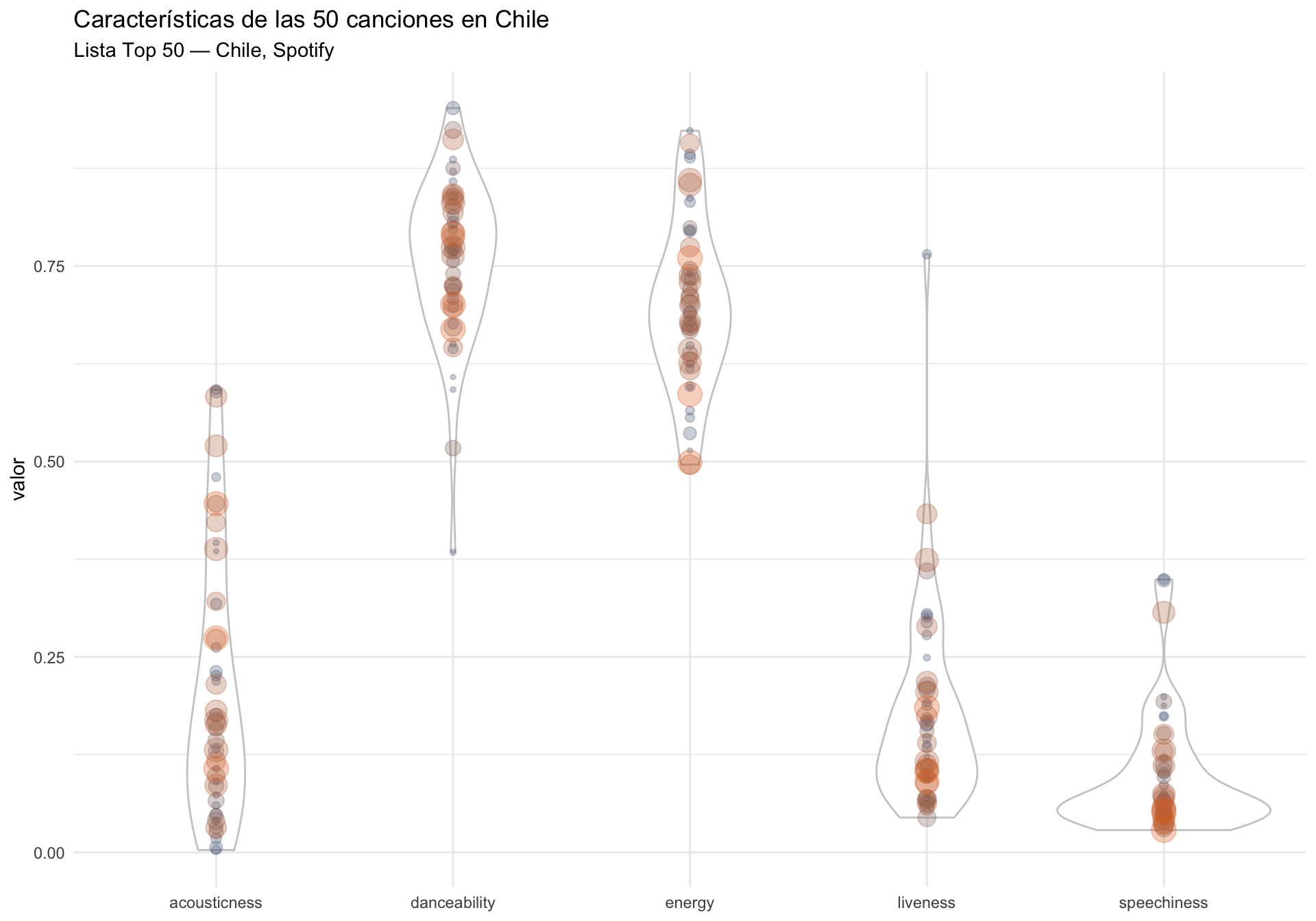
Spotify: spotifyr canciones 1
Con el id de las canciones, podemos obtener características musicales de las canciones.